I bet you’ve heard a colleague say “well, it works on my machine at least” at some point. That’s the last thing you want to hear, because it’s usually uttered in those situations where some system or tool isn’t working, and nobody really knows why.
Testing is certainly not always a walk in the park, which is precisely why there are companies dedicated solely to that. In the IT realm, what’s particularly tricky is examining the matters that lie between different systems. This is typically referred to as “end-to-end” testing.
In this setup, it’s all about one system producing information that another system receives and modifies. After that, the information is sent as an input to a third system.
I’ll open this up through a simplified image.
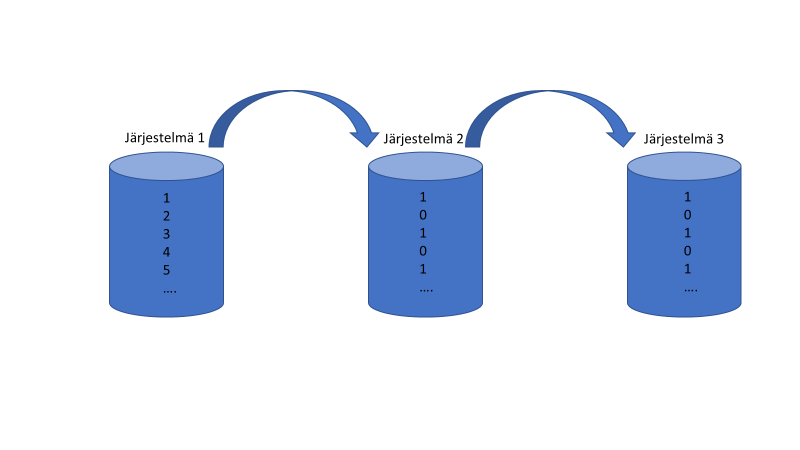
The situation is as depicted in the image above. The first point (on the left) is easy to test. You input data into the system and see if it displays correctly. The last point (on the right) is also easy to test.
You receive information, and if it’s entered into the system correctly, it still looks the same. The middle part presents the most challenges, although in this image it appears simple.
Let’s delve a bit deeper into these challenges through an example. Imagine a simple machine. This machine receives a number and stores the data “0” if the number is even, and “1” if the number is odd.
The functionality can easily be tested. The most obvious method is to feed the numbers 1-10 into the machine and see if the distribution between zeros and ones is 50/50. At this stage, the testing seems straightforward and clear. It’s even hard to imagine what could possibly go wrong. However, in reality, even the simplest things aren’t always as simple as they initially appear.
Many types of testing environments
Let’s dive into environmental matters at this point. In the world of systems, we talk about two types of environments: the production environment and the test environment.
Typically, nobody wants to test anything in a production environment. That’s why there’s a separate testing environment where everything can even be broken without worry. In fact, there can be two testing environments, one for developers and the other intended for end-users.
This suffices when only one system is being tested. Now, as we move on to testing the “end-to-end” process, we should have test environments available for the entire process, and what’s more, they need to be interconnected. In our example case, we must modify data in the system on the left and verify functionality in the system on the right.
When planning testing, it’s crucial to implement enough “end-to-end” test pipelines to ensure things are tested thoroughly.
The ideal system architecture in our example would be as follows:
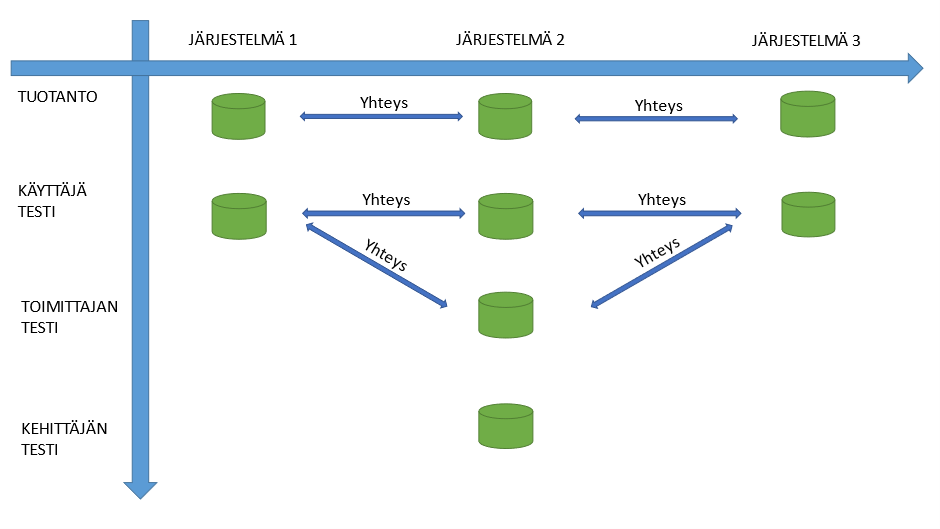
With this structure, developers can test in their own environment without any connections to other systems. The vendor can perform tests at a slightly higher level in their own testing; typically, the connections are unidirectional, or if possible, there are also three instances from other systems (often, for cost reasons, this is not desired).
The kind of system setup described here is rarely ready off the shelf; it typically needs to be implemented, for instance, as part of the delivery of System 2. This usually requires time commitments from multiple parties, as it’s not at all uncommon for all three systems to be created by different vendors, with the infrastructure between the systems managed by the IT department as a whole.
At the planning table, you’ll typically need 3 to 4 different parties to make the whole thing work. It goes without saying that sufficient time needs to be allocated for this.
Exception, exception, exception – how to stop these error messages from popping up?
Now that we have a good grasp on system architecture, we can circle back to testing the secondary system. It’s easy to verify the system operates correctly with numbers 1-10. Let’s input these numbers into the primary system and ensure that the information has been logged correctly.
Just a reminder: system one generates numbers, system two stores information about the numbers being even or odd, and system three prints the information into a PDF file. Typically, system three is tied to some sort of final customer output, which is why it gets the most attention.
Everything should now work without any issues. We are testing the printing. The test halts with an error message “Exception…”, which in programming language means an error.
We forgot about null values in the testing of the secondary system. After all, null is neither even nor odd (the code for this is roughly in the form of i % 2 == 0, where i is the input number, and if the number isn’t initialized, its value is “null” which causes an error).
So, we found a bug in the system. Let’s handle these and continue. This time, we input the number 2.0 into the primary system. Once again, the result is an error report.
This time, it turns out we’re dealing with an incorrect number change, as it was previously assumed that the secondary system would only receive integers as input. Let’s add processing so that the code can be run with non-integer values as well.
After the changes, we’re pleased to finally get the correct values for 2.0, 3.0, and 4.5 down on paper. Great. We can now move forward to production.
Let’s move on to the production phase – wait, not just yet
In production, the first user enters the best possible approximation of Pi into the first system – and yet again, the result is an error message. The next user inputs a number so large that it exceeds the system’s numeric capacity – you can guess the outcome.
At this stage, the punishment of the innocent is likely already in full swing. In reality, we should have clearly defined which numbers can be accepted and notified the first system if an attempt is made to input a number that doesn’t meet the requirements. This way, the system could be guided to instruct the user on how to input the correct types of numbers. Amidst all the rush, these issues have simply slipped through the cracks.
“End-to-end” testing is extremely profitable – and at the same time, planning it is extremely challenging. If the secondary system is built in a vacuum, there’s a high probability of failure.
Designing, implementing, and running tests as shown in the pictures, however, takes time. Time that may not necessarily be budgeted for a project intended to implement another system.
At this point, it’s all too common to skimp on the number of test environments and declare that “this will suffice.” However, this is the phase in testing where mistakes should be identified at the latest. Otherwise, the cost of fixing errors often multiplies significantly.
In this case, we’re not just fixing the error, but we might also have to correct production data that has gone haywire due to an unnoticed mistake.
Another point that also merits attention is the quality of test data.
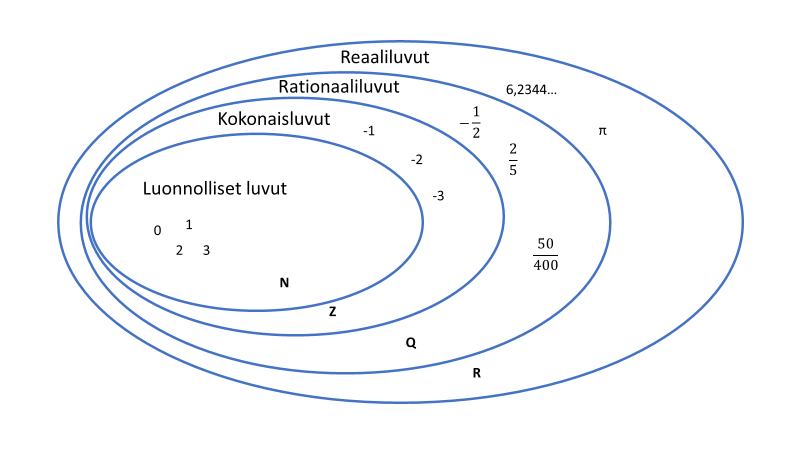
From those group theory classes, we might recall that numbers can be divided into parts, and if the requirement is that the program works for all numbers, we need to be able to select test data from all subsets of numbers.
Data will always be a subset, as testing with all values takes too much time. Testing largely relies on probability calculations, which reduce the likelihood of error to an acceptable level with a sufficient sample size.
The phrase “works on my machine” is something we’ll probably hear at some point, but with good design and smart choices of test data, we can significantly reduce the likelihood of it coming up often.